.svg)
.svg)
Why Scaling Your App Too Early Can Destroy Product Performance
.png)
Premature scaling is one of the most common and most damaging mistakes in software development. According to research on over 3,200 high-growth tech startups, 74% of failures are directly linked to scaling too early, before a product is truly ready. This article unpacks why rushing app scalability backfires, what the warning signs look like, and how founders and product leaders can build smarter from the ground up, without sacrificing speed or momentum.
You've just closed a funding round. The investor deck showed hockey-stick projections. Everyone on the team is fired up, and there's enormous pressure to grow fast. So the engineering team starts migrating to microservices, spinning up cloud infrastructure for a million users, and hiring DevOps specialists. There's just one problem: you still only have 2,000 active users and a product that's still finding its footing in the market.
This is premature scaling. And it doesn't just slow you down... it can quietly destroy the very performance and reliability your users depend on.
The App Scalability Trap Nobody Warns You About
Ask most startup founders what "scaling" means, and they'll describe adding servers, refactoring into microservices, or implementing complex load-balancing architecture. They're not wrong; those are legitimate scaling strategies. The problem is timing.
App scalability isn't about what you build. It's about when you build it.
A monolithic architecture that handles 10,000 concurrent users perfectly is not a problem that needs solving if you're currently serving 500. But when teams feel the pressure to grow — from investors, from competitors, from their own ambition — they often start building for the future at the expense of the present. The result? A bloated, over-engineered system that:
- Takes longer to develop new features
- Introduces more failure points before you've even validated your core product
- Drains engineering resources away from the actual product experience
- Creates performance issues from complexity, not from genuine user load
This is what researchers at UC Berkeley and Stanford found when they studied over 3,200 high-growth tech startups for the Startup Genome Project. Their conclusion was stark: 74% of high-growth internet startups fail due to premature scaling, and a staggering 93% of startups that scale prematurely never break the $100,000 monthly revenue threshold.
The data also showed something counterintuitive: startups that scale prematurely actually write 3.4 times more code in their Discovery phase. More code, more complexity, worse outcomes.
What Premature Scaling Actually Looks Like in Practice
It's easy to read a statistic and nod along. It's harder to recognise the pattern when you're living it. Here's how software scalability issues typically show up in real product teams.
Over-engineering the Architecture Before You Have Users
Microservices are powerful. For the right team, at the right stage, they're a genuinely transformative approach to application architecture. But they also introduce distributed systems complexity, network latency, service orchestration overhead, and significantly harder debugging workflows.
WhatsApp handled 450 million active users with just 32 engineers which is a team smaller than most Series A startups. Stack Overflow ran on a deliberately "boring" monolith for over a decade, serving billions of page views on just nine on-premise servers. The engineers weren't being lazy. They were being smart. They understood that complexity is a cost, and you should only pay that cost when the return is worth it.
If you're building a new SaaS product with 500 paying customers, the return almost certainly isn't worth it yet.
Hiring an Infrastructure Team Before You Have Infrastructure Problems
One of the most telling signs of premature scaling in startups is the early DevOps hire. Bringing on cloud architects, platform engineers, and SREs is entirely appropriate at the right stage. When a team ofeight developers is building the core product, hiring infrastructure specialists often means those people spend their time optimising systems that don't yet need optimising.
This isn't a people problem; it's a sequencing problem. And it's one of the most significant startup growth bottlenecks that founders don't see coming until the burn rate becomes unsustainable.
Rebuilding What's Working Because It "Won't Scale Later"
This one is subtle and pervasive. A team builds a working feature. It's not elegant, but it works. Then someone raises a hand: "This won't scale when we have a million users." So the team stops building new value and starts rebuilding existing value, for a hypothetical future that may never arrive.
The Startup Genome data is instructive here: startups that scale prematurely were found to have 75% more paid users in their early stages compared to consistent startups, yet they still failed. Having more early users doesn't protect you from premature scaling because the problem is structural, not numerical.
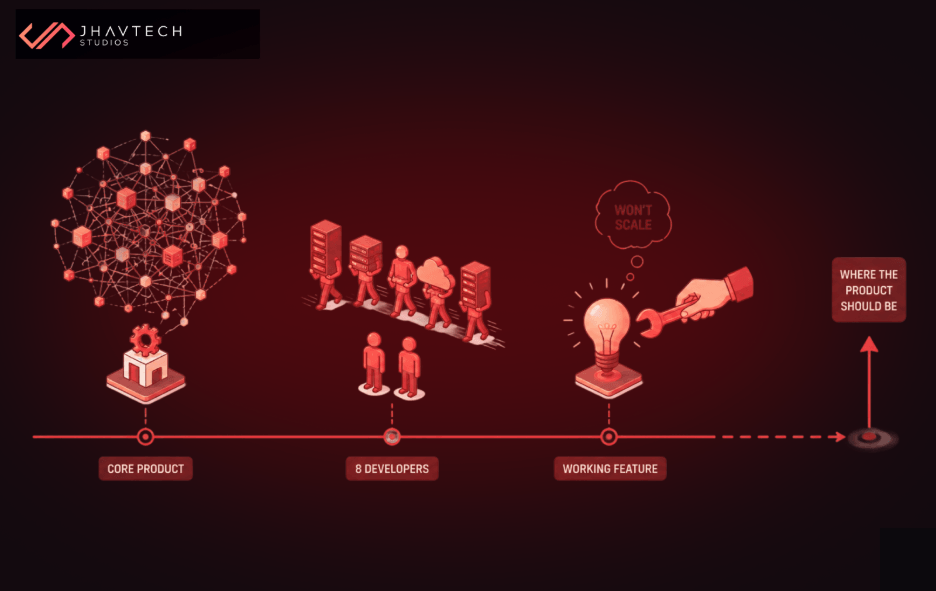
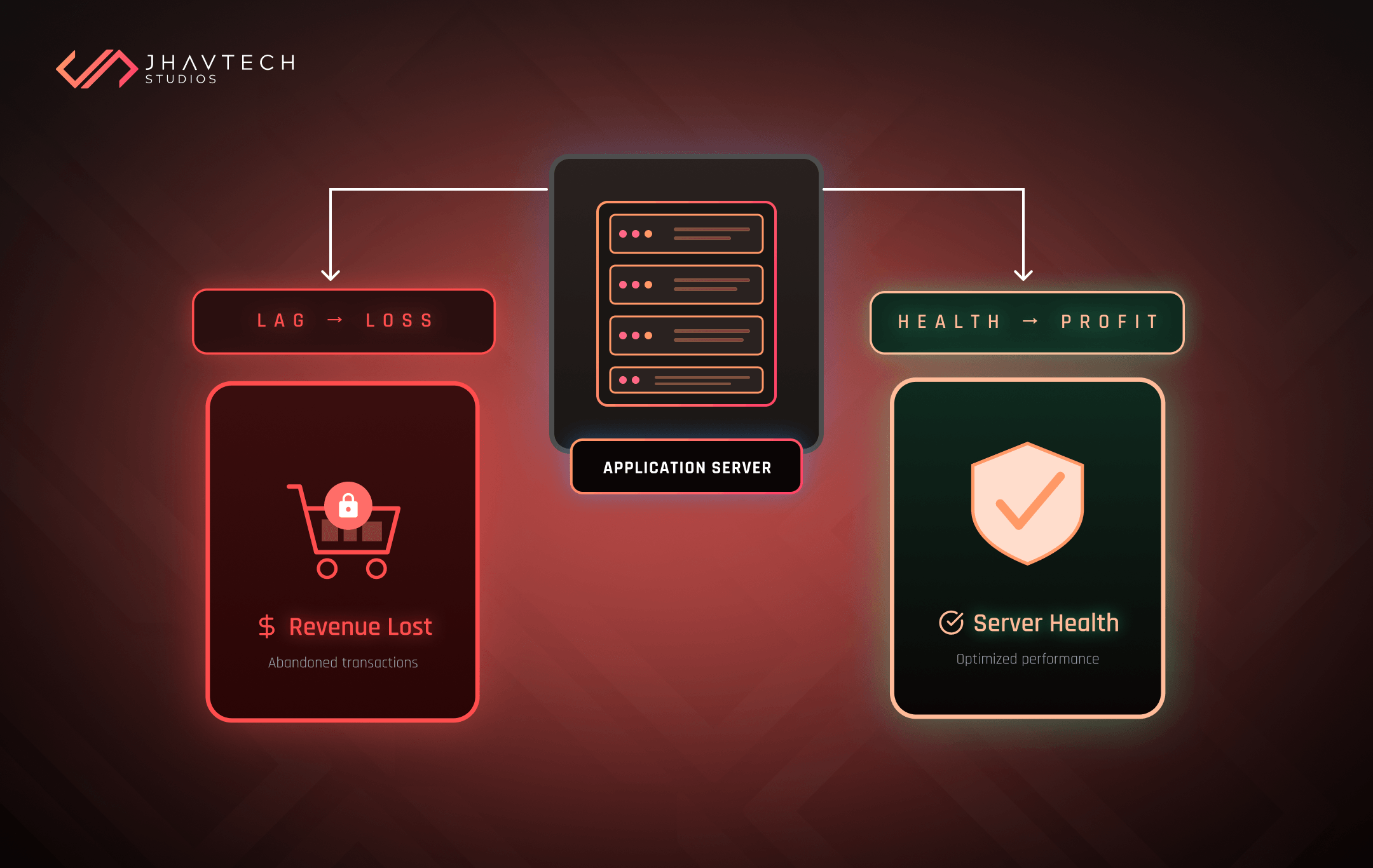
The Real Performance Cost of Scaling Too Early
When product teams talk about application architecture problems, the conversation usually focuses on what breaks when you grow. But premature scaling creates a different category of performance problem: the damage that happens before you're growing.
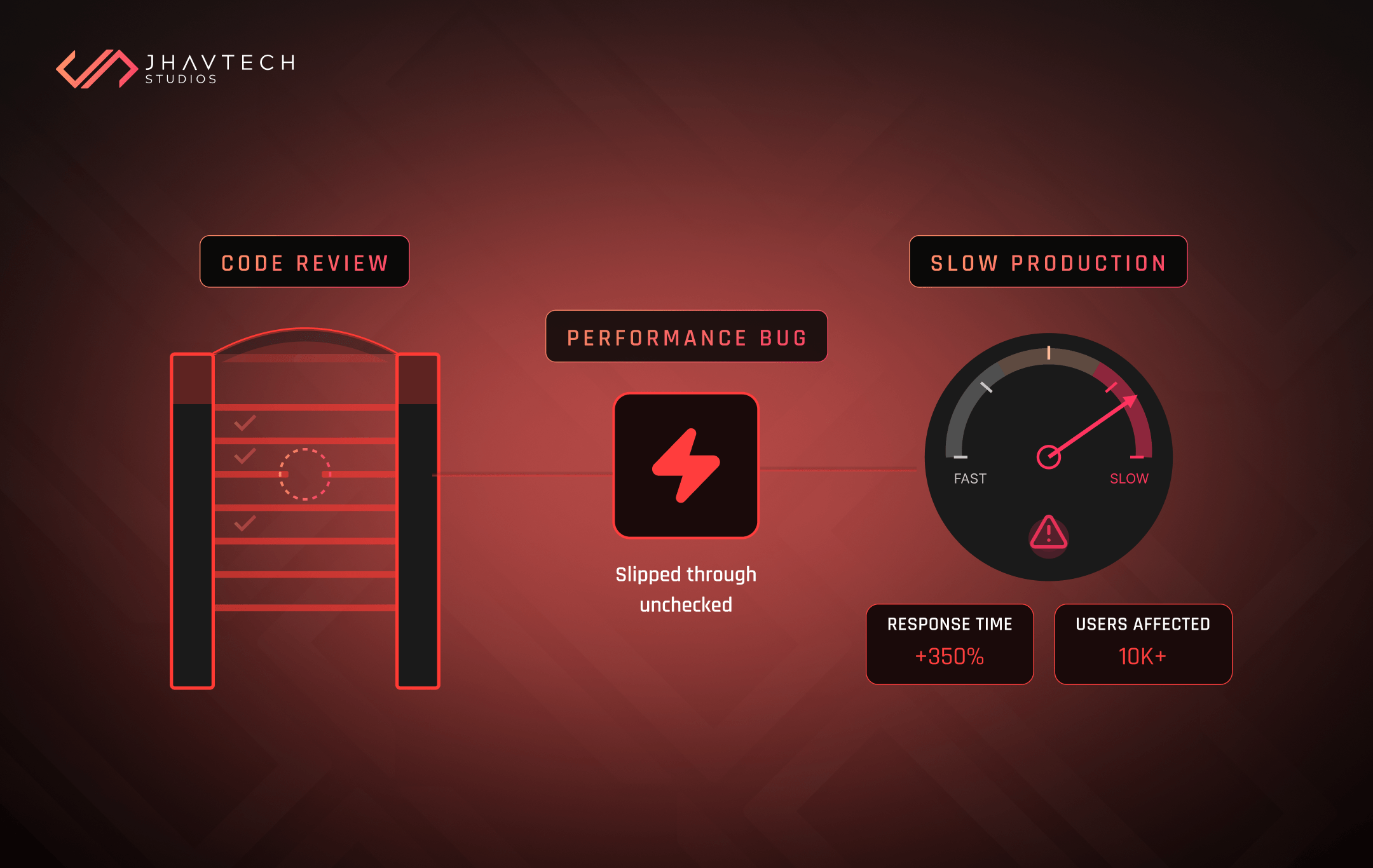
Slower release cycles. When your architecture is complex, every new feature touches more systems, requires more testing, and goes through more deployment hoops. Teams that scaled too early frequently report feature delivery timelines that are 3 to 5 times longer than they expected.
More bugs in production. Distributed systems fail in distributed ways. Each microservice is a new point of failure. Each service-to-service call is a potential timeout. The more components you've introduced prematurely, the more your users will encounter subtle, hard-to-reproduce errors that erode trust.
Developer productivity collapse. When your engineers spend their time managing infrastructure instead of building product, you're not just paying for the infrastructure. You're paying an opportunity cost in lost features, missed user insights, and delayed product-market fit discovery.
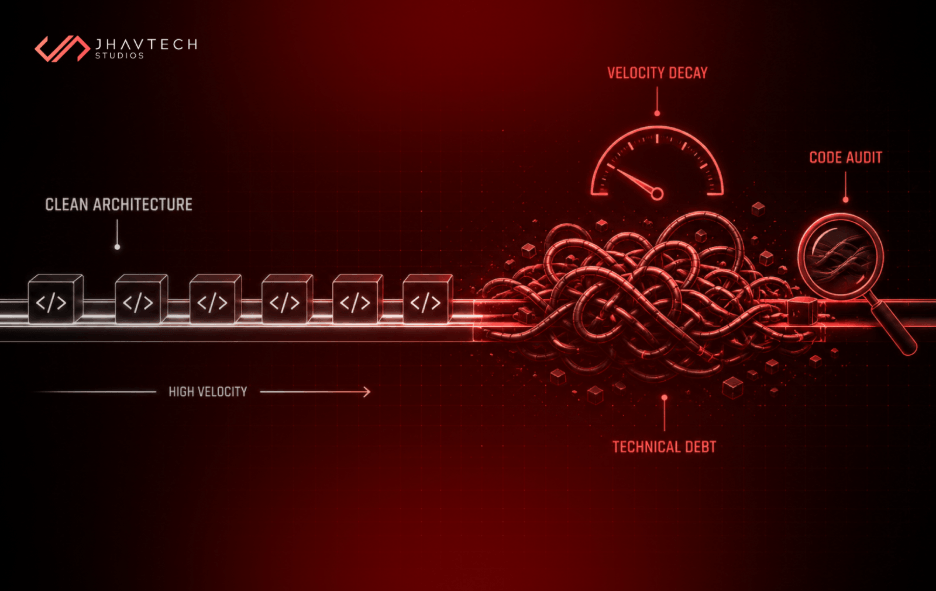
Technical debt disguised as sophistication. Perhaps most insidiously, premature scaling can look like best practice. Microservices, Kubernetes clusters, event-driven architecture — these are all legitimate tools. But deployed too early, they become a specific type of technical debt: architecture that's more complex than the problem actually requires.
Signs Your Startup Is Scaling Too Early
Not every team that's struggling recognises what's happening in the moment. Here are the clearest warning signs that your scaling timeline is ahead of your product maturity:
Your infrastructure costs are growing faster than your user numbers. If you're paying for capacity you're not using (even by 30%) that's a meaningful signal worth investigating.
New features take significantly longer to ship than they used to. Architectural complexity that outpaces team size almost always shows up here first.
Engineers spend more time on system maintenance than on product development. A useful rule of thumb: if your engineers are spending more than 20-25% of their time on infrastructure that isn't directly tied to a known user problem, you may be over-scaled for your current stage.
Performance issues exist despite low user volume. This is a major red flag. If your app is slow or unreliable with a small user base, the problem isn't capacity — it's architecture. Adding more infrastructure will compound the issue, not resolve it.
Your product-market fit conversations are vague or uncertain. If you're not yet confident about exactly who your best customers are and why they stay, scaling your infrastructure is getting ahead of the most important problem you have to solve.
When Should You Think About App Scalability?
None of this means you should ignore scalability entirely in your early builds. The goal isn't to build something fragile and throw it away later. It's to make deliberate, well-timed decisions about when to introduce complexity.
Here's a practical framework for thinking about scaling readiness:
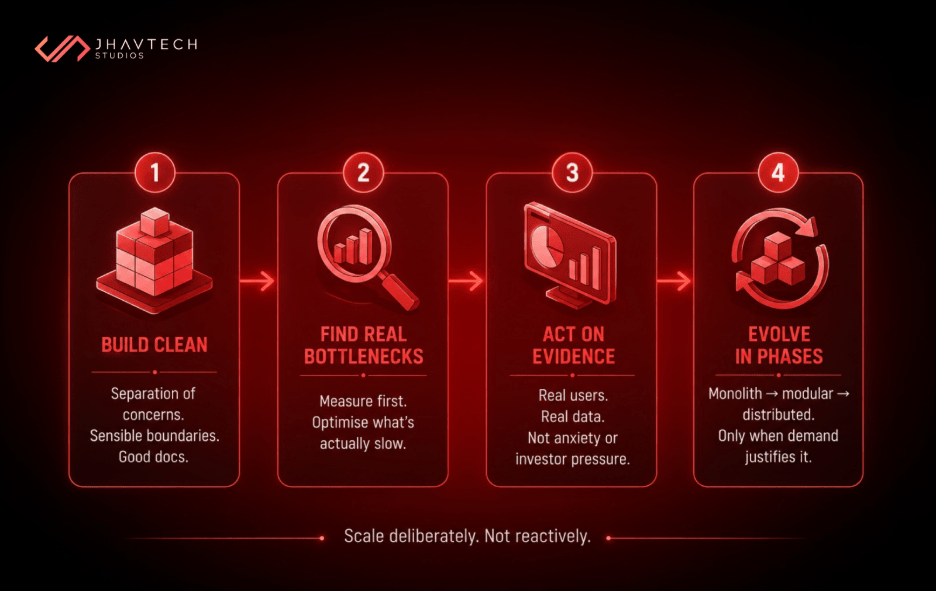
Build Clean, Not Complex
Write code with clear separation of concerns. Use sensible module boundaries. Document your APIs well. This isn't premature optimisation, it's laying groundwork that makes future scaling significantly cheaper and faster. The cost of clean code is minimal. The cost of refactoring tangled code is enormous. If you're unsure how your current codebase holds up, a free code audit is a low-risk way to find out before the problems compound.
Identify Your Actual Bottlenecks Before Solving Imaginary Ones
Before adding infrastructure, identify where performance is degrading. Use real metrics. If your database queries are slow with 1,000 users, optimise those queries. Don't build a caching layer, a message queue, and a read replica cluster before you've confirmed the query optimisation won't solve the problem.
Scale When You Have Evidence, Not Anxiety
The right trigger for scaling is evidence of constraint. This refers to real users experiencing real performance issues, specific bottlenecks that observability tools have confirmed, conversion or retention data that points to a performance problem. Anxiety about future scale is not a trigger. Investor pressure is not a trigger. Competitive fear is not a trigger.
Consider Your Architecture in Phases
Leading engineers describe a sensible evolution: keep it simple in the early stage (a well-structured monolith usually beats a premature microservices architecture), identify your highest-load components and extract them first as you grow, then introduce event-driven patterns and advanced DevOps practices when you have the team and the real-world demand to justify them. This mirrors what's worked for companies that scaled successfully. It's a phased approach, not a big-bang redesign.
The Hidden Link Between Premature Scaling and Project Failure
There's a pattern worth highlighting here that connects scaling decisions to broader project outcomes.
When teams over-invest in infrastructure too early, they typically underfund product iteration. They have less capacity to respond to user feedback, less flexibility to pivot when the market signals something unexpected, and less tolerance for the kind of experimentation that produces genuine product-market fit.
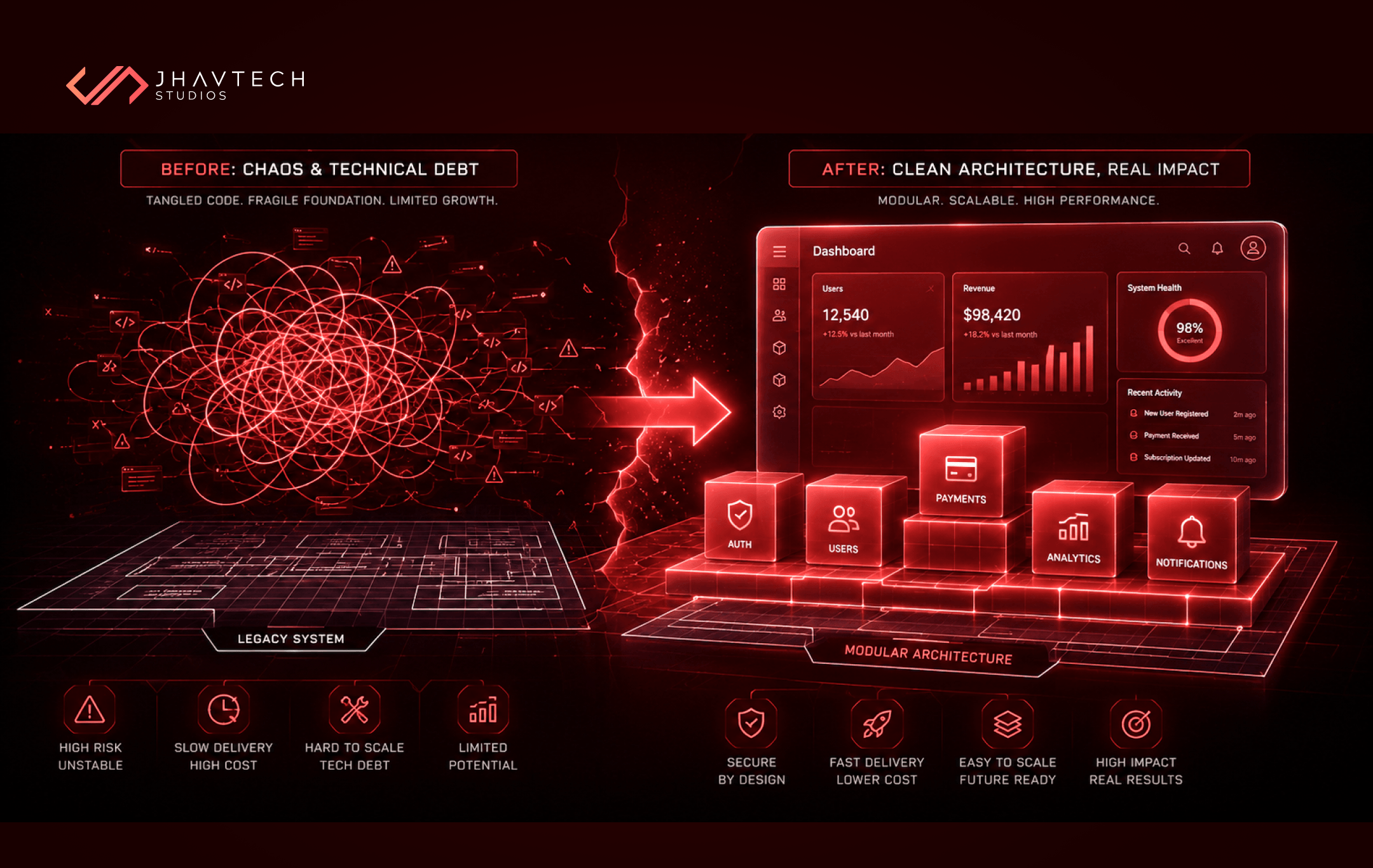
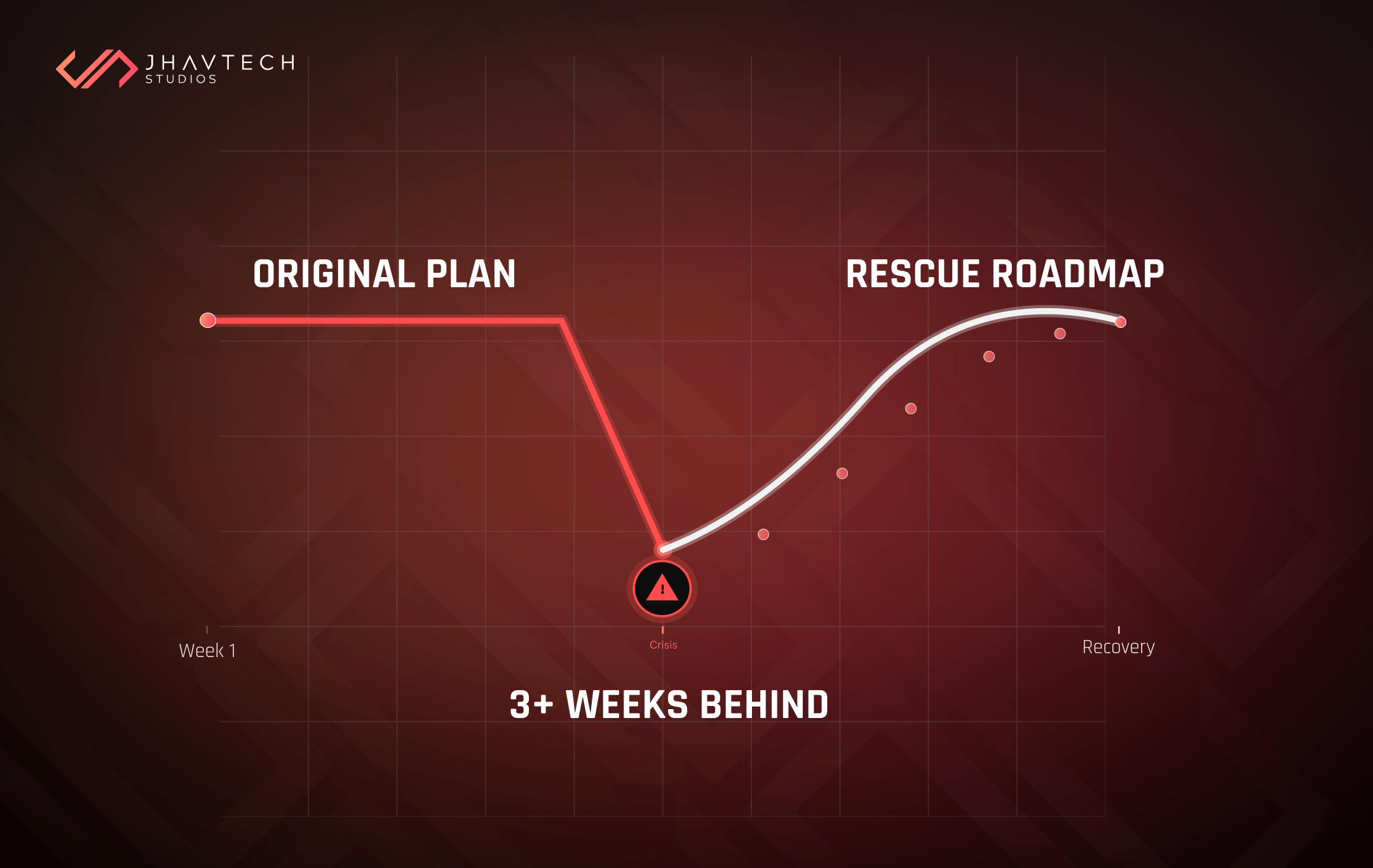
This is exactly what the hidden cost of delayed software projects looks like in practice — not just missed deadlines, but compounding losses in trust, momentum, and market position. Premature scaling is, in many ways, a form of delay in disguise: you're building the wrong things, which delays the time it takes to build the right ones.
And when a scaling problem reaches critical mass, teams are often faced with a more difficult choice: attempt a costly and risky refactor mid-flight, or accept the performance degradation and lose users. Neither is a good option. The far better approach is building deliberately from the beginning, which is something expert-led software development can help you design right the first time, rather than reconstruct at great expense later.
What to Do If You've Already Scaled Too Early
If you're reading this and recognising your current situation in what's described, the good news is that it's recoverable. The path forward involves being honest about what exists, what it costs, and what it would take to simplify.
Start with an architecture audit. Understand what you have, what it costs to run and maintain, and what problems it's actually solving. Not what it was designed to solve — what it's solving right now, for the users you actually have.
Then prioritise ruthlessly. Not every over-engineered component needs to be tackled at once. Identify the parts of your system that are actively hurting performance or slowing development velocity, and start there.
If the situation is complex or the team is too close to the problem to see it clearly, an external technical review can provide the objective perspective you need. Sometimes the most valuable thing an outside engineering team can offer is the ability to call a spade a spade and recommend a pragmatic path forward without the internal politics that make those conversations difficult.
That's precisely where a structured technical rescue engagement can make a meaningful difference. Having an experienced team map your existing architecture, identify the bottlenecks that actually matter, and provide a clear remediation plan can save months of engineering effort and prevent the painful user churn that performance degradation inevitably causes.
You might also find value in our guide on what happens in the first 48 hours of a software project recovery — it's a practical look at how to triage, stabilise, and reset a project that's drifted off course.
Building for the Growth You Have, Not the Growth You Hope For
The best product teams think about app scalability the way experienced engineers think about everything: with evidence, pragmatism, and a clear-eyed understanding of the trade-offs involved.
Building for 10 million users when you have 500 is not ambition, it's distraction. It's a form of premature optimisation that delays the discovery of what your product actually needs to become. The startups that scale successfully are, almost without exception, the ones that resist the temptation to build for a future they haven't yet earned, and instead obsess over delivering a reliable, performant experience for the users they already have.
Validated growth, deliberately supported by architecture that evolves in step with real demand, is how durable products get built.
Scalability Readiness Checklist
Before you scale, run through this
Use this checklist to gauge whether your product is genuinely ready to scale or whether you're about to over-invest in infrastructure you don't yet need.
☐ You have confirmed product-market fit with repeatable retention data
☐ Observability tools (logs, metrics, traces) are in place and being actively monitored
☐ You have identified a specific, measurable bottleneck — not a hypothetical one
☐ Simpler solutions (query optimisation, caching, indexing) have been ruled out first
☐ Your team has the operational maturity to manage the added complexity
☐ Infrastructure costs are proportional to actual (not projected) user load
☐ Feature delivery velocity is not already suffering under the current architecture
☐ You have load-tested against realistic traffic projections, not worst-case fantasies
If you're ticking fewer than five of these, you're likely not ready to scale, and that's a good thing to know before you spend the budget.
Frequently Asked Questions About App Scalability
.png)
.png)
.png)
.png)

.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)



.png)
.png)

.png)



.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)

.png)

.png)

.png)
.png)

.png)
.png)
.png)
.png)
.png)


.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)

.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)

.png)
.png)
.png)












