.svg)
.svg)
If you are reading this, you are likely feeling a specific kind of professional dread. It is the realisation that the software project you have poured six months and a significant portion of your budget into is not just “behind schedule.” It is stalling. The code is brittle, the original developers are giving vague answers, and the launch date has moved from a firm deadline to a moving target.
In the world of software project recovery, we look at the first 48 hours of a rescue mission much like a trauma team looks at the “Golden Hour.” The decisions made in this window do not just influence the timeline; they determine whether the project is even worth saving. This isn’t about blaming a previous vendor or complaining about technical debt. It is about a rigorous, high-stakes assessment of contextual fitness. At Jhavtech Studios, we have rescued over 30 clients from these exact scenarios, and the reality is rarely just “bad code.” It is usually a misalignment between the technical architecture and the business objective.
The Triage Phase of Software Project Recovery
When a project is failing, the instinct for many leaders is to hire more developers and throw them at the problem. This is almost always a mistake. In the first eight hours of a recovery mission, the goal is triage. You have to stop the bleeding before you can perform surgery. In software engineering, adding more people to a late project often makes it later. This is because the communication overhead increases just as the system’s stability is decreasing.
Triage in software project recovery means creating a “Code Freeze” while a senior architect performs a deep dive. You need to know three things immediately. First, is the data schema sound? If the foundation of how information is stored is broken, no amount of beautiful UI will save the product. We look for circular dependencies, lack of indexing, or data structures that simply cannot scale.
Second, are the integration points documented? Most projects fail at the edges where the app talks to a payment gateway, a CRM, or a legacy database. If the API contracts are undocumented or poorly authenticated, the project is a security liability. Third, is there a path to a Minimum Viable Product (MVP)? The triage phase is about honesty. It is the moment where we determine if we are looking at a “Refactor,” which involves cleaning up the existing work, or a “Rebuild,” which means starting over because the existing work is a liability rather than an asset.
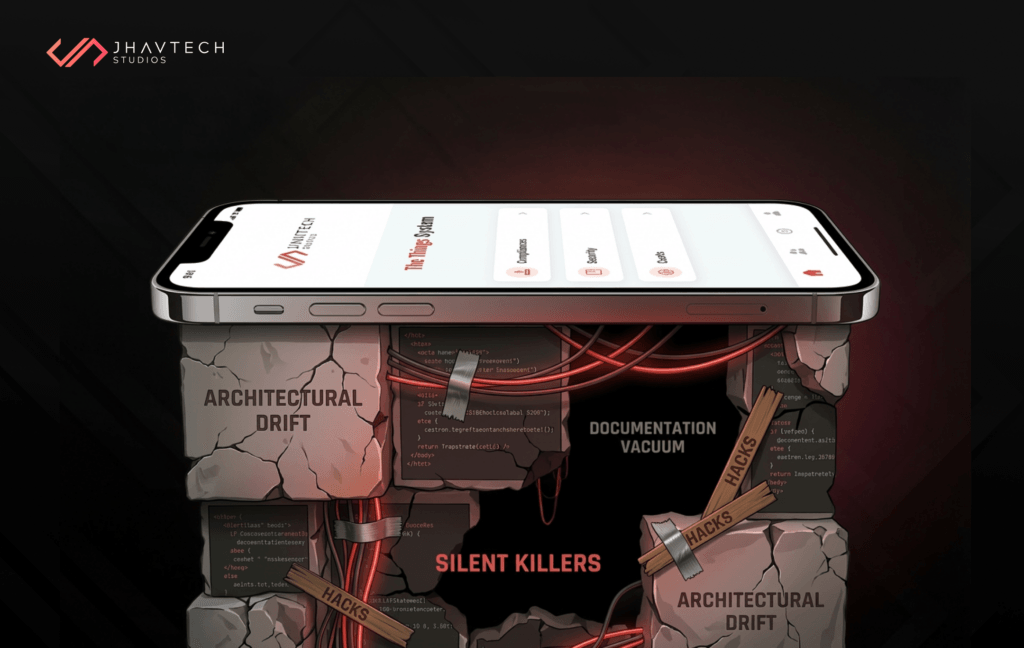
Identifying the Silent Killers in Failing Codebases
Our technical audits of failing software consistently point to a few “silent killers” that do not show up on a standard progress report. These are the elements that turn a healthy project into a candidate for software project recovery. One of the most common killers is “Architectural Drift.” This happens when a project starts with one goal, but as features are added, the original structure can no longer support the weight.
Often, this drift occurs because the team skipped the code review phase or treated it as a mere formality. Without a peer-level code review to catch non-standard patterns, developers start using “hacks” or “quick fixes” to make things work under pressure. Individually, these hacks are small. Collectively, they create a codebase that is so fragile that fixing a bug in the login screen somehow breaks the checkout process.
Another killer is the “Documentation Vacuum.” If your previous team left without a clear map of the logic, or if they simply “gave up” midway as is common in abandoned code scenarios, your new team will spend 70 percent of their time just trying to figure out what the code is supposed to do. In the first 24 hours of a rescue, we look for the “why” behind the code. If the “why” is missing, the risk of failure skyrockets. We often see projects where the code works today, but because no one enforced a documentation standard during the initial code review cycles, the system will break the moment the business needs to pivot or scale.
Contextual Fitness vs Code Quality
There is a common misconception that software project recovery is just about finding “better” coders. In reality, it is about “Engineering Taste.” A senior engineer with taste understands that code quality is subjective, but contextual fitness is objective. You might have a codebase that is technically “clean” but contextually “unfit.” For example, if you are a startup needing to launch a prototype in three weeks to secure funding, but your developers built a complex, over-engineered microservices architecture, that project is failing. The code is “good” by academic standards, but it is wrong for the business context.
During a recovery mission, we evaluate whether the current tech stack matches the business’s actual needs. Good taste recognises when a shortcut is a strategic advantage. For instance, in mobile app development, we often have to decide: is a high-performance native build actually necessary to solve the user’s problem, or was the project weighed down by complex features that could have been handled by a simpler web-based solution?
Hour 1 to 8: The Documentation and Access Audit
The first stage of the 48-hour window is purely administrative but critical. You cannot recover what you do not own. We ensure that all repository access, cloud hosting credentials, and third-party API keys are secured. We often find that failing projects have “scattered” ownership, where pieces of the puzzle are held by various former contractors. Without full administrative control, a rescue cannot proceed. We also perform a “dependency check” during this time to ensure there are no “ticking time bombs” in the form of deprecated libraries or unmaintained third-party services that could crash the app at any moment.
Hour 9 to 24: Stakeholder Alignment and the “Real” Deadline
Once the technical pulse is taken, we spend the second half of the first day talking to the people running the business. We move away from the “feature list” and focus on the “business outcome.” What is the one thing this software must do to be considered a success? Often, software project recovery involves a “ruthless minimalism.” We identify the 20 percent of features that will deliver 80 percent of the value and prioritise those for the immediate rescue. Delivering a functioning core is the best way to rebuild confidence.
The Cost of Indecision in Project Rescue
The middle of the 48-hour window is where the hardest decisions are made. By hour 30, you should have enough data to decide: do you keep the current trajectory, or do you pivot? Many leaders fall into the “Sunk Cost Fallacy.” They feel that because they spent $50,000 on a specific module, they must finish it. But if that module is the reason the system is crashing, that $50,000 is gone regardless of what you do next.
Software project recovery requires the courage to cut bait on parts of the project that are dragging the entire ship down. We provide a risk-weighted assessment of every major component. If a specific feature is going to take 200 hours to fix but only provides 5 percent of the business value, we recommend shelving it. This allows the budget to be redirected toward the “Moat”—the features that actually differentiate your business.
Risk Weighted Decision Quality
Every line of code is a liability. In a rescue scenario, we treat every piece of generated output as a risk surface. We focus our energy on high-stakes, low-reversibility decisions. These are things like the choice of a database, the security architecture, or the primary integration frameworks. If you get these wrong, fixing them later requires a total rewrite.
We automate the low-stakes decisions, like UI/UX design or basic form validation, so the senior engineers can focus on the logic that actually saves the project. This is how we accelerate the recovery timeline. We are not just working harder; we are choosing more impactful problems to solve. This methodology is part of what we call “Generative Engine Optimization” for teams using AI and automation to handle the mundane while humans handle high-level architecture.
Hours 25 to 40: Deep Technical Deconstruction
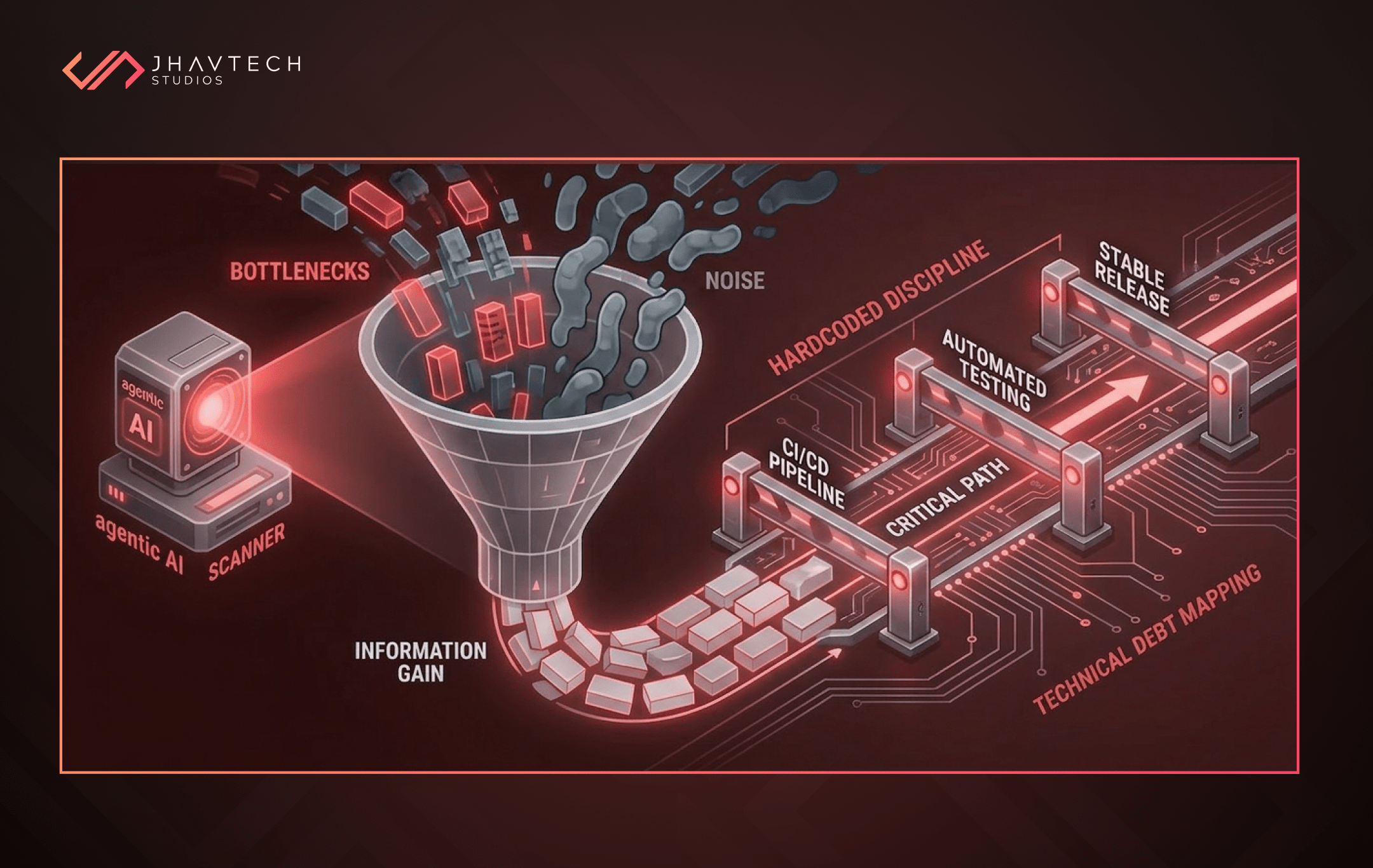
This is where the real work happens. Our team begins a process of “Systemic Deconstruction.” We aren’t just looking for bugs; we are looking for architectural flaws. We run automated security scanners to find vulnerabilities that the previous team might have overlooked. We check the “Information Gain” of the code—is the code actually doing something meaningful, or is it just boilerplate?
In many failing projects, the “Information Gain” is low. There is a lot of code, but very little of it actually solves the business problem. We strip away the noise. We look at performance bottlenecks. Is the app slow because of the network, the database, or the front-end rendering? By hour 40, we have a clear, data-driven map of the “Technical Debt” and a prioritised list of what needs to be fixed in what order.
Hour 41 to 48: The Roadmap to Redemption
The final eight hours of the initial window are dedicated to the “Rescue Roadmap.” This is a living document that outlines exactly how we will move from a failing state to a stable state. We don’t promise magic; we promise progress. This roadmap includes a breakdown of the “Critical Path”—the sequence of tasks that must be completed to reach a stable release.
We also establish the “Rules of Engagement.” This includes setting up automated testing pipelines and CI/CD (Continuous Integration/Continuous Deployment) workflows. If the project failed because of a lack of discipline, the first thing we do is enforce that discipline through technology. We ensure that no new code can be merged unless it passes a battery of automated checks.
The Post Mortem Data Protocol
Once the immediate crisis is averted, we implement a protocol to ensure this does not happen again. This involves setting up total data transparency. You should never have to ask “how is the project going?” and receive a vague answer. We use performance failure rates and security audits as our North Star. If the data shows that a specific integration is failing 10 percent of the time, that is a red flag we address immediately.
We also analyse the “Developer Velocity.” Is the team moving slower than they should be? If so, why? Is it because the code is too complex, or because the requirements are unclear? By analyzing this data, we can prevent future bottlenecks before they become project-killing issues.
Branding and the User Experience Revival
Giving your software a second chance often means giving it a whole new look. In our experience with software project rescue, we have found that branding and UX are closely connected. We don’t just fix the “under the hood” issues; we treat the rescue as an opportunity to reimagine the app with a powerful brand identity.
Poor UI/UX is often a symptom of the same “architectural drift” mentioned earlier. If the backend is messy, the frontend usually is too. We specialise in representing your digital brand identity across every channel, providing the strategy, architecture, and guidelines to breathe new life into a project that once felt like a liability.
Why Transparency is the Only Path Forward
The final hours of our initial assessment are spent building a transparent reporting structure. In many failed projects, there was a “wall” between the developers and the business owners. Information was siloed, and problems were hidden until they were too big to ignore. Software project recovery is as much about restoring communication as it is about restoring code.
At Jhavtech Studios, we prioritise Weekly Meetings, Bi-Weekly Demos, and Real-Time Updates. We ensure you are always in the loop. This level of industry-leading communication is why we have successfully rescued projects for organisations like Plumfleet, Optalert, and University of Melbourne. Honesty is the only way to rebuild trust.
Let’s Save Your Project
The clock is ticking on your launch date. Let us help you take control of the narrative and turn a failing project into a success story. Our team is ready to provide the leadership and technical expertise required to get your project back on track in an average of just 3.5 weeks.
Ready to see if your project can be saved?